If your company’s ERP system dates back to the AS/400 glory days, your users are likely accustomed to running programs that generate “old school” spool file output. While working with printed reports was quite common in the past, today most users prefer to work in a more paperless fashion, opting for on-screen apps or downloaded spreadsheets wherever possible.
In cases where spool file output is created through RPG logic in conjunction with printer files, Valence 5.2 includes a tool to help you convert the report output into a grid widget through Nitro App Builder, provided you have access to the RPG source code. With a relatively quick retrofit of the program, instead of sending a spool file to an OUTQ your users can simply launch an app in Valence to get the same data in an interactive grid, downloadable to a spreadsheet if they so choose. Using basic NAB functionality you could further dress up the app with additional UI elements, such as a chart or graph. This month’s tip shows you how this RPG retrofit is done, while still retaining the program’s ability to create spool files when needed.
Qualifying the program: time required to run…
Before embarking on the “webification” of a spool file-generating RPG program, it’s important to first determine if the existing report is an appropriate candidate for being run quasi-interactively as a Valence app.
In the early days of the AS/400 platform it was common for report-generating RPG programs to take quite a few minutes to run, thus necessitating they be submitted to batch so as not to lock up an interactive green screen session for too long, or overload the QINTER subsystem, while the data was being crunched. But with today’s Power Systems being many times more powerful than the legacy hardware, many of these formerly long-running reports can now be run in a matter of seconds.
Completion time is key. For an optimal user experience, you typically don’t want your users to have to wait an excessive period to get the output they’re looking for once they click on an app. So if the RPG program generating a report can be run in a reasonable amount of time, i.e., within a half minute, then the program is a good candidate for conversion into an “on-demand” Valence app.
Demo program included with Valence
For demonstration purposes, we will use the EXPRINT RPG program included in VALENCE52 to show how this retrofit might be achieved. Our goal in this process is to allow the program to continue working in “legacy” mode to produce spool file output, while at the same time being able to conditionally support working in “Valence” mode.
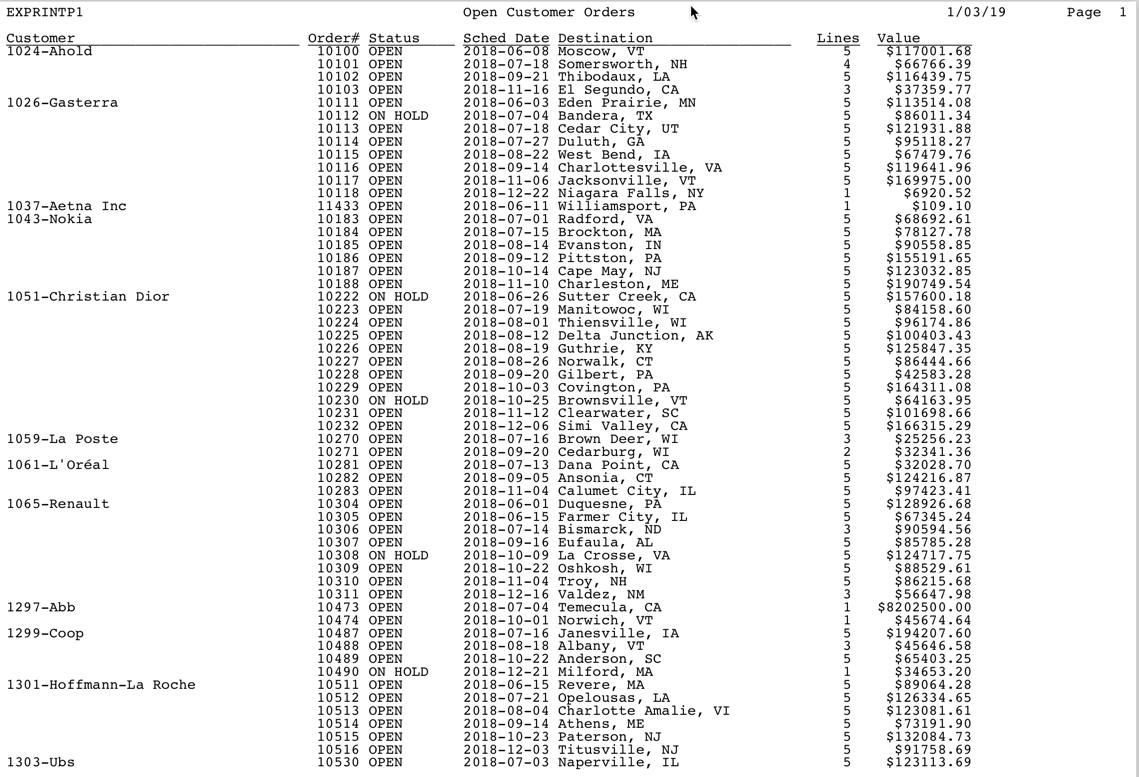
You can see original spool file output of this program by going to a command line and typing CALL EXPRINT PARM(‘PRT01’), replacing PRT01 with the desired OUTQ on your system. On older Valence builds you may first need to compile the the print file EXPRINTP1 in QDDSSRC and the RPG program in QRPGLESRC. The resulting spool file looks like this:
Creating work file(s) for the grid app
When you’re ready to begin the process of retrofitting an RPG program to work as a NAB app, the first step is to create work file(s) to hold the data that was formerly being sent to print file record formats. For each “detail” record format the RPG report writes to you will need an equivalent work file definition, each of which will be used as a separate data source for the resulting grid app.
If you’re running Valence release 5.2.20181030.0 or later, there is a utility program called VVCRTWRKF you can use to speed up the process of creating the work file definitions. With VALENCE52 and the library holding your print file in your library list, you can access the utility from a green screen command line via CALL VVCRTWRKF.
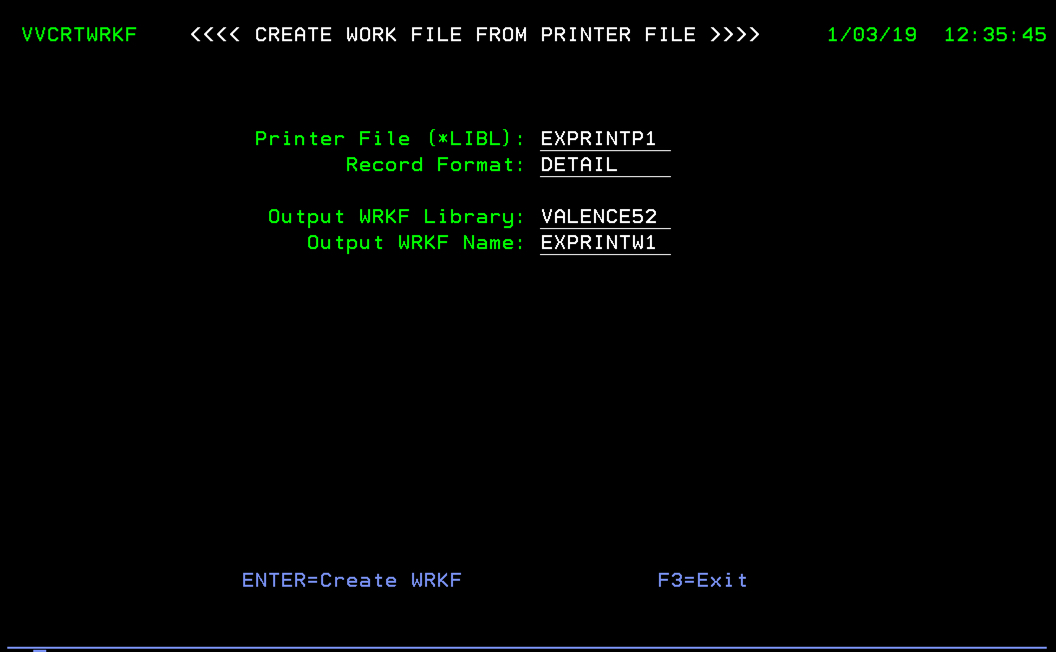
In this example we’re extracting the DETAIL record format from print file EXPRINTP1 and creating a *FILE object called EXPRINTW1. The next step in the retrofit process is to modify the RPG program that populates this print file, EXPRINT, to plug data into this EXPRINTW1 file object when serving as a data source to a Valence NAB app. The manner in which we do this will depend on how the data is being served up to the front-end.
The “load-all” approach
It’s important to consider how many records the report being retrofitted for Valence typically produces, as this will have a bearing on how we use the underlying work file(s). If you’re looking at less than a thousand records in total, the time it takes to stream the data to the user’s browser and assemble it into a grid is relatively negligible — a “load all” list will work fine. But if there are potentially many thousands of records in the report, streaming the data in its entirety to the browser is generally not recommended. In such cases you will want the user to be able to page through the data.
Both scenarios can be made to work with the work file override technique, but it will change the approach. For load-all lists, we can simply make a copy of the work file in QTEMP, load it up, then immediately stream its contents to the front-end. By using QTEMP we don’t need to worry about other users running the same report at the same time and mixing up data, as the QTEMP copy of the file is specific to just the CGI job processing the request.
This load-all approach is how EXPRINT has been retrofitted. Let’s review the modifications in the source file now to understand how it’s done (note that all Valence retrofit-related modifications have a “/vv” mod mark in the left column). Afterward we’ll address what we’d do differently for a page-at-a-time approach.
(1) F Spec Adjustments
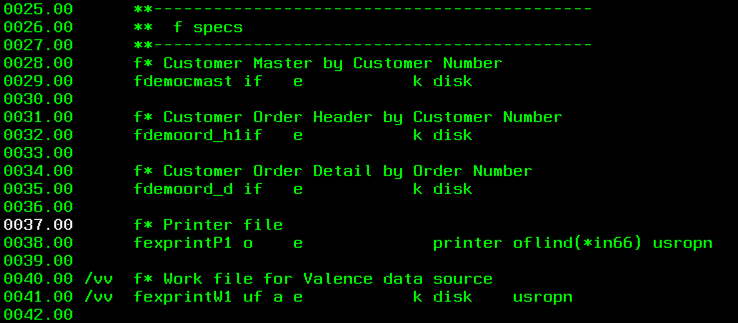
Our first step is to add the work file(s) to the F Specs. We’re doing this instead of using SQL because writing to a work file via native IO closely mimics the way data is output to a print file, which means less code.
(2) Global D Spec Adjustments
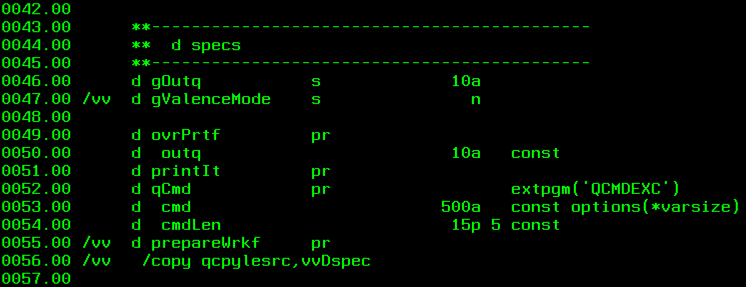
The next step in our retrofit is to add a global indicator to tell the program when we’re in “Valence” mode, and copy in the Valence D-Specs so we can bring in Valence RPG Toolkit procedures. Though more recent IBM i OS compilers don’t require it, to be thorough we’ll also include the prototype definition for the “prepareWrkf” procedure we’ll be adding.
(3) Initialization Code
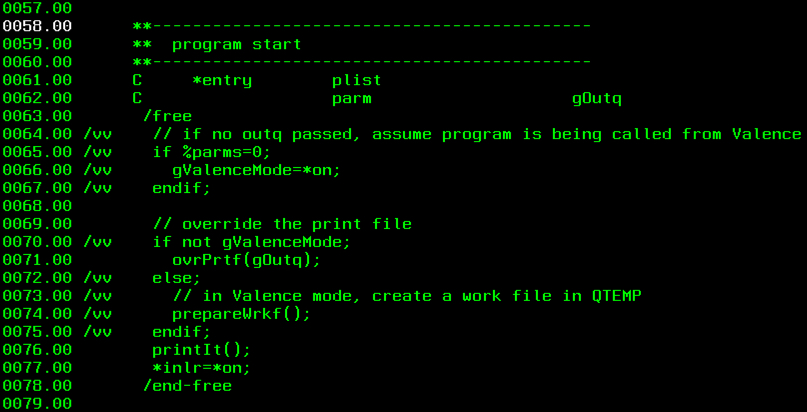
At the beginning of the program we need to determine if we’re running in “Valence mode” and set the global indicator accordingly, which will be used throughout the program. We will do this by creating a wrapper program EXPRINTW that receives the call from NAB and calls EXPRINT without passing any parameters. Lines 65-67 will detect this type of call and set the indicator accordingly. Then we’ll call the prepareWrkf procedure to prepare our work file, EXPRINTW1, for use later in the program.
(4) Work file setup
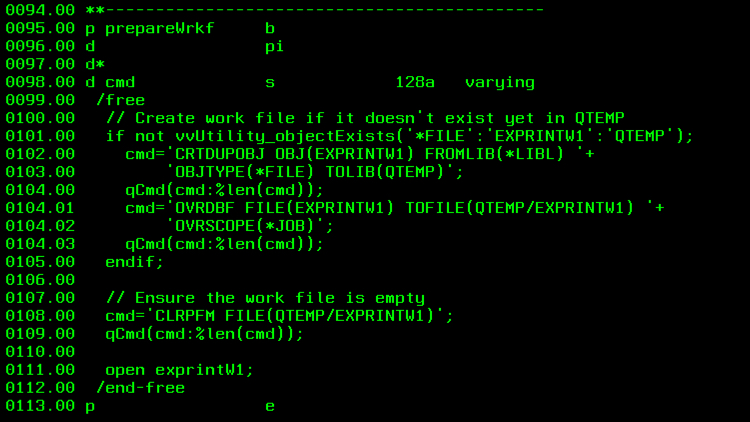
For our load-all approach, the prepareWrkf routine first checks to see if a copy of the EXPRINTW1 work file has already been placed into QTEMP to serve the job. If it hasn’t, then it copies it in. Subsequently it does a CLRPFM to ensure the file is empty. If QTEMP is not at the top of your library list, you may also want to add a job-level OVRDBF command to ensure the QTEMP copy of the file is used by this RPG program and the downstream operations that will pull data from it.
(5) Print logic adjustments
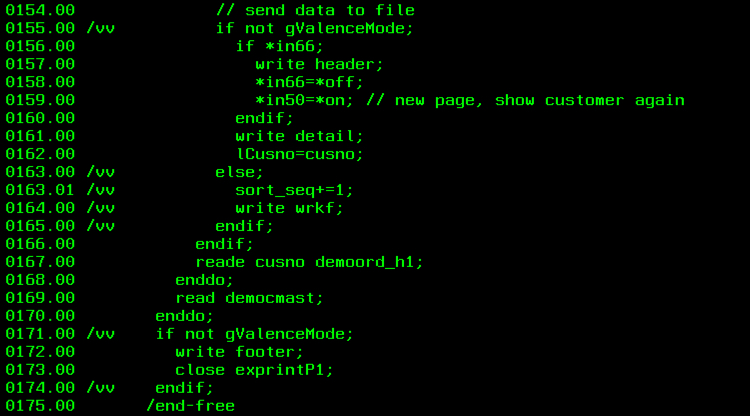
The last step in the RPG retrofit process is to redirect output from the print file record format(s) to the corresponding work file(s). To accommodate this we add conditional checks of our “Valence mode” global variable to decide when to circumvent writes to the print file in favor of writes to the appropriate work file. The work file automatically includes a sort_seq field that we can use to ensure the sequence of data written to the file is retained when later pulled into our Valence grid app.
Creating the front-end NAB app
With the back-end set up to populate work files, we’re now ready to turn our focus to the front-end. Using Nitro App Builder, this part of the process is pretty straightforward. If you’re not already familiar with this process of creating a grid app, please check out the Nitro App Builder videos on the CNX Resources web page.
First, create a data source that selects all the pertinent data columns from the work file (in this case, EXPRINTW1). Note that since the work file does not yet exist in QTEMP, you’ll need to temporarily place a copy of it in a library that your Valence instance can see in order to select it as a data source.
On the data source save panel, in the space for a Pre-Execution Program, be sure to specify the name of an RPG program that will receive the call from NAB and subsequently call the RPG program that creates the printed output. In our example here, we have a simple “wrapper” program called EXPRINTW that simply calls EXPRINT with no parameters, which is its signal that it’s running in “Valence mode” rather than a normal call.

Once the data source is created and saved, proceed to create a simple grid widget over it. In addition to overriding the column headings with appropriate text, be sure to turn off paging in the UI configuration. In the example spool file you can see that orders are loaded and clustered by customer, so we can turn on grouping over the customer column to mimic that in the web output.
Finally, create an app that uses your newly created grid widget and you’re ready to roll! The final product should look something like this:
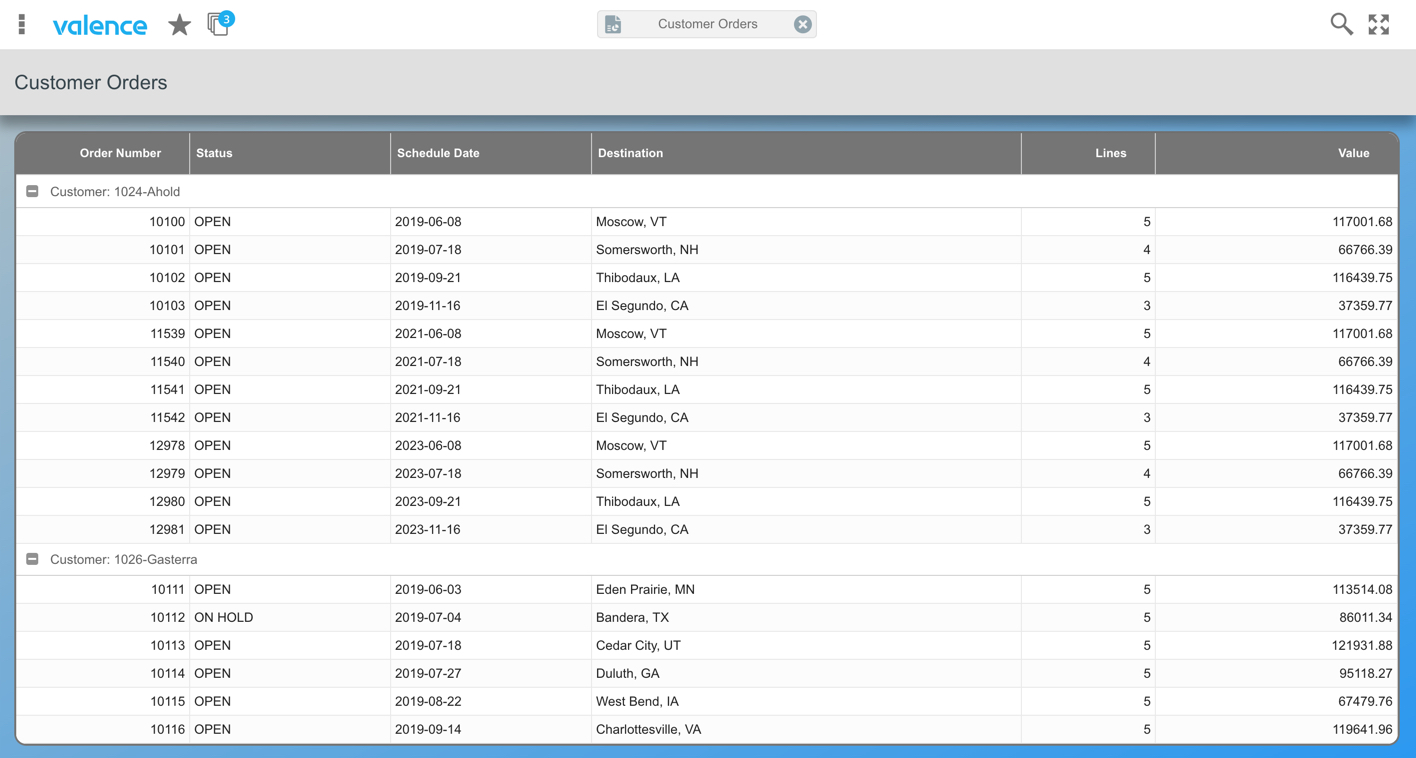
Considerations for page-at-a-time loads
The example above assumes we’re working with a smaller volume of output, where we can load all the report records into QTEMP and then stream them in one fell swoop to the browser. For longer reports containing thousands of rows this “load all” concept is not a practical approach as it can overwhelm the browser’s local memory. In such cases the grid application will instead need to page through the data on separate calls, which means we cannot use the QTEMP approach because there’s no guarantee the same CGI job that created and populated the QTEMP file for the first page will be called again when moving on to the second page. Instead we’ll need to store the work file data in a regular library with a special key unique to the user’s session.
In addition to pulling all the fields used in the print file record format, any work file created by VVCRTWRKF also includes a couple special fields for internal use in your RPG program and data source: SORT_SEQ to help retain the output sequence (if you populate this field as you write records you can add it to your data source’s “Order By” clause), and SESSION_ID to optionally hold the Valence session ID. It’s the session ID field that we’ll use to accommodate paging.
If you’re on the latest Valence build (5.2.20190218.0 or later), then you can tell the data source to use the current session ID in the “Where” clause using the new VVIN_PARM() SQL procedure. For all apps running in the Valence Portal, the session ID is globally available as ‘sid’ so your where clause can be: SESSION_ID = VVIN_PARM(‘sid’)
Since your work file in this page-at-a-time scenario is no longer “self cleaning” by virtue of being in QTEMP, you may also want to add a cleanup routine to the Valence instance. You can do this by specifying an exit program for the LOGOUT process in Portal Admin > Settings > Exit Programs > Session Logout. See line 120.00* of the example RPG program EXEXITPGM in your Valence library to see how such an exit program routine can be coded to automatically purge expired session records from the work file. (* If you’re using a Valence build prior to 5.2.20190218.0, just search for the “LOGOUT” section.)
One final point to consider when doing page-at-a-time loads: The pre-execution RPG program associated with the data source is called on every call to retrieve data. This means it’s not only called on the initial load but also on each subsequent page load as users page forward or backward through the data. To avoid the overhead of reloading the entire work file on each new page, consider adding logic to only load the work file when pulling the first page. Your RPG program can know when it’s the first page by checking the value of “page” via VVIN_NUM(‘page’). If it’s a 1 then you know it’s loading the first page; if it’s greater than one then you can assume the data has already been loaded on a prior call and skip the work file load.